![]()
Durable workflow engine backed by Postgres or SQLite. Define a workflow as a graph of steps (activities, decisions, terminal states) and the engine persists every step's result, picks up where it left off if a worker dies, and keeps a full journal of what happened. Multiple workers can process executions concurrently with lease-based coordination.
npm install @prsm/workflowOptional storage adapters:
npm install sqlite3
npm install pgimport WorkflowEngine, { defineWorkflow } from '@prsm/workflow'
const workflow = defineWorkflow({
name: 'review',
version: '1',
start: 'fetch',
steps: {
fetch: {
type: 'activity',
next: 'route',
retry: { maxAttempts: 3, backoff: '5s' },
run: async ({ input }) => ({ message: input.message.trim() }),
},
route: {
type: 'decision',
transitions: { spam: 'reject', normal: 'complete' },
decide: ({ data }) => (data.message.includes('buy now') ? 'spam' : 'normal'),
},
complete: {
type: 'succeed',
result: ({ data }) => ({ outcome: 'sent', message: data.message }),
},
reject: {
type: 'fail',
result: ({ data }) => ({ name: 'Spam', message: data.message }),
},
},
})
const engine = new WorkflowEngine()
engine.register(workflow)
const execution = await engine.start('review', { message: ' hello ' })
await engine.runUntilIdle()
const result = await engine.getExecution(execution.id)
console.log(result.status) // "succeeded"
console.log(result.output) // { outcome: "sent", message: "hello" }| Type | Purpose |
|---|---|
activity |
Run application code, then move to one explicit next step |
decision |
Choose one route from a fixed transitions map |
wait |
Suspend the execution until an external signal or timeout |
subworkflow |
Spawn a child workflow and wait for it to terminate |
succeed |
End the workflow successfully |
fail |
End the workflow with a failure |
{
type: "activity",
next: "publish",
timeout: "30s",
retry: { maxAttempts: 3, backoff: "5s" },
run: async ({ input, data, steps, step, signal }) => {
console.log(step.idempotencyKey)
return await doWork(input, { signal })
},
}{
type: "decision",
timeout: "10s",
transitions: {
approved: "publish",
rejected: "reject",
},
decide: ({ data, steps }) => "approved",
}The chosen route is persisted in the step state and execution journal.
If decide() returns a route name that is not in transitions, the step fails and normal retry/failure rules apply.
Decision steps have no default timeout. If your decide() function calls external services, set timeout explicitly or a hanging call will block the worker indefinitely. Activity steps default to defaultActivityTimeout (30s); decisions and terminal steps default to no timeout unless you set one.
A wait step parks the execution in suspended status until something external delivers a signal. No handler runs while it waits. Use it for human approvals, external webhooks, queue messages, or any other "we cannot proceed without an outside event" gate.
{
type: "wait",
timeout: "7d",
transitions: {
approved: "publish",
rejected: "archive",
timeout: "remind",
},
resolve: ({ signal, data, steps }) => signal.decision,
}resolve maps the signal payload to one of the routes in transitions. If you omit resolve, the engine looks for payload.route instead.
Resume the execution by calling engine.signal(executionId, payload). The payload is recorded as the step's output for downstream steps and audit. signal() is idempotent: a duplicate call throws AlreadySignaledError and the execution is unchanged.
If timeout is set, the engine fires the special timeout route automatically when the timer expires. Defining a timeout requires defining the timeout transition.
A subworkflow step starts a child workflow and waits for it to reach a terminal status. Same suspended machinery as wait, just driven by the child's terminal event instead of an external signal.
{
type: "subworkflow",
workflow: "kyc-check",
version: "2",
input: ({ data, steps }) => ({ userId: data.userId }),
transitions: {
succeeded: "continue",
failed: "reject",
canceled: "reject",
},
}All three terminal routes (succeeded, failed, canceled) are required. The step's output is { executionId, status, output, error } describing the child's terminal state, accessible via steps[stepName].output in later steps.
Canceling a parent execution cascades to any suspended children. A child that terminates while its parent is no longer suspended is a clean no-op - the child's work still runs to completion in case it produced useful side effects.
A workflow definition can be pure JSON. Instead of inline functions, steps reference named handlers from a catalog you pass to defineWorkflow. This makes definitions storable in a database, editable through a UI, and producible by tooling - while the code that actually runs stays in your reviewed, tested handler catalog.
const handlers = {
trim: ({ input, params }) => ({ message: input.message.trim() + params.suffix }),
route: ({ data, params }) => (data.message.includes(params.word) ? 'spam' : 'ok'),
approval: ({ signal }) => signal.decision,
accept: ({ data }) => ({ outcome: 'sent', message: data.message }),
}
const definition = {
name: 'review',
version: '2',
start: 'clean',
steps: {
clean: { type: 'activity', handler: 'trim', params: { suffix: '!' }, next: 'route' },
route: {
type: 'decision',
handler: 'route',
params: { word: 'buy now' },
transitions: { spam: 'rejected', ok: 'gate' },
},
gate: { type: 'wait', handler: 'approval', transitions: { approved: 'accepted', rejected: 'rejected' } },
accepted: { type: 'succeed', handler: 'accept' },
rejected: { type: 'fail' },
},
}
engine.register(defineWorkflow(definition, { handlers }))Each step type has exactly one function slot, so a single handler field is unambiguous:
| Step type | Handler binds to |
|---|---|
activity |
run |
decision |
decide |
wait |
resolve |
subworkflow |
input |
succeed |
result |
fail |
result |
A step may not define both the function and a handler. Referencing a handler that is not in the catalog fails at definition time.
params is an optional plain JSON object on any step (data-defined or inline). It is passed to the step's function as context.params, cloned per invocation. Use it to keep deployment- or workflow-specific configuration in the definition while the handler stays generic.
handler and params are included in graph nodes, so introspection tools can display exactly which code a step runs and with what configuration.
Workflows are acyclic by default - a back-edge is a definition-time error. Some processes genuinely loop, though: a reviewer requests changes and the draft goes back for revision, a deploy fails verification and rolls back to rebuild. Set cycles: true on the definition to allow transitions that route back to an earlier step.
const workflow = defineWorkflow({
name: 'publish-article',
version: '1',
start: 'draft',
cycles: true,
steps: {
draft: { type: 'activity', next: 'render', maxPasses: 5, run: applyEdits },
render: { type: 'activity', next: 'review', run: renderPreview },
review: {
type: 'decision',
transitions: { changes: 'draft', approved: 'done' },
decide: ({ data }) => (data.changesRequested ? 'changes' : 'approved'),
},
done: { type: 'succeed' },
},
})When a completed step is re-entered, the engine resets its state for a fresh pass: status, attempts, output, and error are cleared, and a pass counter increments. Each pass gets a new retry budget and a new idempotency key (<executionId>:<stepName>:<pass> from the second pass onward), so external side effects deduplicated by key run once per pass, not once per execution. Every re-entry is recorded in the journal as step.reentered.
maxPasses is an optional per-step guard against runaway loops. When routing would push a step past its limit, the routing step fails with step "<name>" exceeded maxPasses=<n> and normal retry and failure rules apply. Steps without maxPasses can loop without limit.
const engine = new WorkflowEngine({
storage, // defaults to in-memory
leaseMs: '5m', // how long a worker owns an execution before another worker may reclaim it
leaseRenewInterval: '100s', // how often the lease is renewed while a step is running (defaults to leaseMs / 3)
defaultActivityTimeout: '30s',
owner: 'node-a', // worker identity written into claims and checked on save
batchSize: 10, // max executions to claim and process concurrently per polling cycle
maxJournalEntries: 100, // cap journal size, 0 = unlimited (default)
})Core methods:
engine.register(workflow)
engine.unregister(name, version)
await engine.start(name, input, options?)
await engine.runDue(options?)
await engine.runUntilIdle(options?)
await engine.startWorker(options?)
await engine.getExecution(id)
await engine.listExecutions(filter?)
await engine.cancel(id, reason?)
await engine.pause(id, reason?)
await engine.resume(id)
await engine.restartUnder(id, options?)
await engine.signal(id, payload)
engine.describe(name, version?)register and unregister work at any time, not just at startup, so workflow versions can be added and removed while workers are running. In-flight executions of an unregistered version will fail to process until it is registered again, so unregister a version only after its executions have drained or been restarted under a newer version.
| Method | What it does |
|---|---|
start(name, input) |
Create a persisted execution |
runDue() |
Process ready executions once, then return |
runUntilIdle() |
Keep calling runDue() until nothing is immediately runnable |
startWorker() |
Poll forever on a timer, calling runDue() each interval |
runUntilIdle() is useful in tests and scripts. startWorker() is what you use in production.
Create the engine once, register workflows, start the worker loop. Trigger workflows from routes, jobs, or anywhere else.
// workflows/engine.js
import WorkflowEngine from '@prsm/workflow'
import { postgresDriver } from '@prsm/workflow/postgres'
import { triageWorkflow } from './triage.js'
export const engine = new WorkflowEngine({
storage: postgresDriver({ connectionString: process.env.DATABASE_URL }),
owner: `worker-${process.pid}`,
leaseMs: '30s',
})
engine.register(triageWorkflow)
engine.on('execution:succeeded', ({ execution }) => {
console.log('done:', execution.id, execution.output)
})
engine.on('execution:failed', ({ execution }) => {
console.error('failed:', execution.id, execution.error)
})
await engine.startWorker({ interval: '100ms' })// routes/tickets.js
import { engine } from '../workflows/engine.js'
router.post('/', async (req, res) => {
const execution = await engine.start('triage', {
subject: req.body.subject,
message: req.body.message,
})
res.json({ executionId: execution.id })
})For tests and local prototypes:
import { memoryDriver } from '@prsm/workflow'Single-node durable storage:
import WorkflowEngine from '@prsm/workflow'
import { sqliteDriver } from '@prsm/workflow/sqlite'
const engine = new WorkflowEngine({
storage: sqliteDriver({ filename: './workflow.db' }),
})Shared storage for distributed workers:
import WorkflowEngine from '@prsm/workflow'
import { postgresDriver } from '@prsm/workflow/postgres'
const engine = new WorkflowEngine({
storage: postgresDriver({
connectionString: process.env.DATABASE_URL,
}),
})The Postgres adapter uses atomic claiming and owner-guarded saves so only one worker can acquire a ready execution, and a stale worker cannot overwrite a newer claimant's state.
Each execution stores:
status:queued | waiting | running | suspended | paused | succeeded | failed | canceledcurrentStepsteps[stepName]- persisted state for each stepjournal- timeline of what happened during the execution- final
outputorerror
Each step stores:
statusattemptsoutputerrorstartedAtendedAtroutepassidempotencyKey
Step idempotency keys are stable per execution and pass:
<executionId>:<stepName> first pass
<executionId>:<stepName>:<pass> later passes (cyclic workflows)Use them for external side effects.
Workflow definitions expose a serializable graph of nodes and edges:
const { graph } = engine.describe('review')
// graph.nodes - step name, type, label, retry config, timeout
// graph.edges - from, to, label (route name for decisions)@prsm/devtools uses this to render live workflow visualization alongside execution state, journals, and step output:
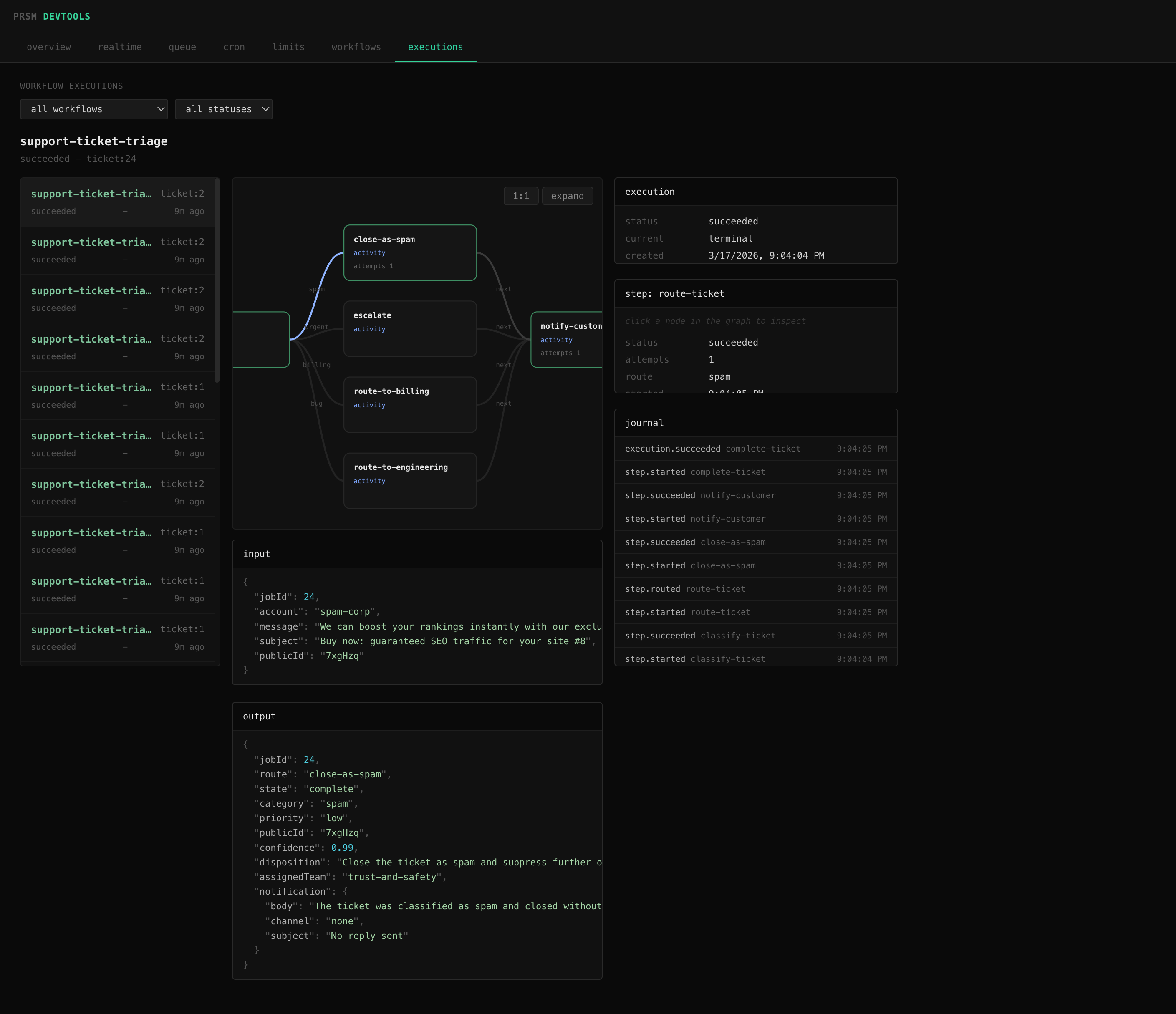
Execution lifecycle - use these to sync external state (update your database, push to websockets, trigger alerts):
engine.on('execution:queued', ({ execution }) => {})
engine.on('execution:paused', ({ execution }) => {})
engine.on('execution:succeeded', ({ execution }) => {})
engine.on('execution:failed', ({ execution }) => {})
engine.on('execution:canceled', ({ execution }) => {})Step lifecycle - use these for logging, metrics, or debugging:
engine.on('step:started', ({ execution, step, attempt }) => {})
engine.on('step:succeeded', ({ execution, step, output }) => {})
engine.on('step:routed', ({ execution, step, route, to }) => {})
engine.on('step:retry', ({ execution, step, attempt, error, availableAt }) => {})
engine.on('step:failed', ({ execution, step, attempt, error }) => {})
engine.on('step:suspended', ({ execution, step, timeoutAt, childExecutionId }) => {})
engine.on('step:resumed', ({ execution, step, route }) => {})Worker health:
engine.on('execution:lease-lost', ({ executionId, step }) => {})
engine.on('worker:error', ({ error }) => {})When an activity step returns a plain object, it is shallow-merged into execution.data via Object.assign. Subsequent steps see the merged result in context.data. Arrays, primitives, null, and undefined are stored in step.output but not merged.
All context fields passed to step handlers are cloned - mutations inside a handler do not affect stored execution state.
Every activity, decision, and terminal handler receives an AbortSignal as context.signal. The engine aborts it when the step exceeds its timeout, when the worker loses the execution's lease, or when the execution is canceled while the step is in flight. Forward it to anything that supports one (fetch, a database driver, a child process) so abandoned work stops instead of running against an execution that has already moved on:
{
type: "activity",
next: "store",
timeout: "10s",
run: async ({ input, signal }) => {
const res = await fetch(input.url, { signal })
return { body: await res.json() }
},
}The signal is advisory. A handler that ignores it still runs to completion, but its result is discarded once the step has timed out or the lease is gone, and the engine applies the normal retry and failure rules.
engine.pause(id, reason?) halts any non-terminal execution. Paused executions are never claimed by workers, cannot be signaled, and stay exactly where they are until resumed.
await engine.pause(executionId, 'pending human review')
await engine.resume(executionId)Pause records the status it interrupted and resume restores it: a queued execution re-queues, a suspended wait step goes back to waiting for its signal with its original timeout deadline intact, and an execution paused mid-step re-queues at that step. Pausing while a step is in flight uses the same discard semantics as cancellation - the running handler's abort signal fires, its result is thrown away, and the step re-runs from scratch after resume. Both transitions are recorded in the journal as execution.paused and execution.resumed.
engine.resume(id) re-queues a failed execution from the step that failed. The step's attempt counter is not reset - resume gives the step exactly one more execution attempt. If that attempt fails and the retry budget is already exhausted, the execution fails immediately.
When a workflow definition changes, in-flight executions stay pinned to the version they started on. engine.restartUnder(id, options?) moves an execution to a different version explicitly: it cancels the old execution (if it is not already terminal), starts a new one under the target version carrying over input, data, metadata, and tags, and links the two in both journals.
const next = await engine.restartUnder(executionId, { version: '3' })
// next.restartedFrom -> old execution id
// old execution's journal gains execution.restarted with the new idPass input, data, metadata, or tags in options to override what is carried over. The new execution starts from the workflow's start step - completed work is not replayed, so make step side effects idempotent if a restarted execution may repeat them.
Every step start, completion, retry, routing decision, and terminal event is appended to execution.journal. By default the journal is unbounded. Set maxJournalEntries to cap it:
const engine = new WorkflowEngine({
maxJournalEntries: 100, // keeps the most recent 100 entries
})When the limit is reached, older entries are dropped.
Workflow graphs are versioned and static. activity steps run code and move to one next step. decision steps choose one named route from a fixed map. Terminal steps end the execution.
Workers claim ready executions using a lease and process them concurrently (up to batchSize per polling cycle). While a step is running, the worker renews that lease. If the lease expires, another worker can reclaim the execution. Saves are guarded by lock owner so a stale worker cannot commit after losing ownership.
Marking a step succeeded and advancing currentStep to its successor happen in a single owner-guarded write. There is no moment where a step is recorded as done but the execution still points at it. A crash therefore leaves the execution in one of two states: the completing write never landed, so a reclaiming worker re-runs the step (at-least-once), or it did land, so the reclaiming worker resumes from the next step. A step that finished is never run a second time.
That covers a crash between steps. For a side effect that happens within a step and then crashes before the step result is saved (the step sends an email, then dies), the step itself will be retried, so make the side effect idempotent. Each step exposes a stable idempotencyKey (<executionId>:<stepName>) you can pass to external services for deduplication.
The package includes integration tests for:
- atomic claiming across competing Postgres workers
- recovery after stale lease expiry
- lease renewal for long-running steps
Run them with:
make up
npm test
make downmake install
make test
make typesMIT